 R&D
R&D Dependence on a shared gem: one of the downsides of a multi-app architecture.
Dependence on a shared gem: one of the downsides of a multi-app architecture.
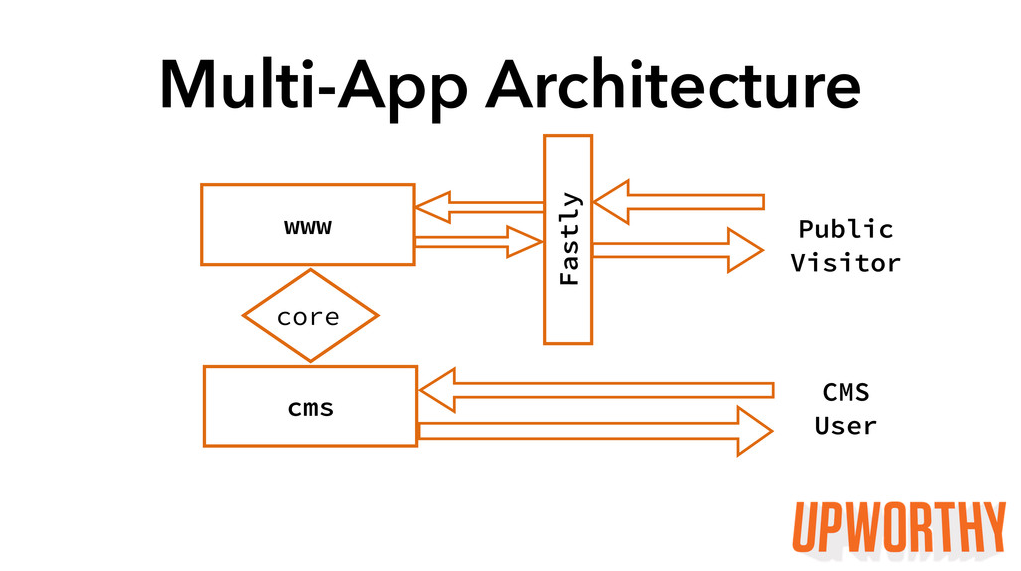
18 months ago, we wanted to improve our site’s stability and scalability, so we re-architected a monolithic Rails app into two separate Rails apps that communicated through a shared database.
One app was a CMS for our Editorial team, and the other was our WWW app presenting content to our readers. These apps used a gem to share code for the models they both depended on (things like a story model, a writer model, etc.). We got some great wins from that redesign:
- Stability: Each app was insulated from traffic spikes or outages affecting the other.
Scalability: We could scale the apps on separate machines that were appropriately priced and configured for their differing needs.
 But, we also encountered some problems:
But, we also encountered some problems:Our development process could get bogged down in managing our gem: To QA our shared code on a staging environment, we had to cut a release candidate version of our gem. If two developers were working on changes to the gem at the same time but on separate branches, they would both cut the same release candidate version for the gem, and one branch would clobber the other. One developer’s code wouldn’t work on staging, but there was no indication to that developer that the release candidate they were using didn’t actually contain the code they had pushed.
- Our test suite wasn’t comprehensive: When we changed code in our gem, we needed to be sure those changes were safe for any dependent code in either of the two Rails apps. Each of the Rails apps was housed in a separate Git repo, which meant that none of our commit scripts ran the code for all three code bases (WWW, CMS, and the gem), even though those code bases were interdependent. We had to remember to manually run all three tests suites. Sometimes we did not remember.
We still wanted to be able to scale and deploy our apps separately, but we discovered a new requirement: We also wanted to share code between these two apps in such a way that our development process would be streamlined and our apps’ dependencies would be testable in a single suite.
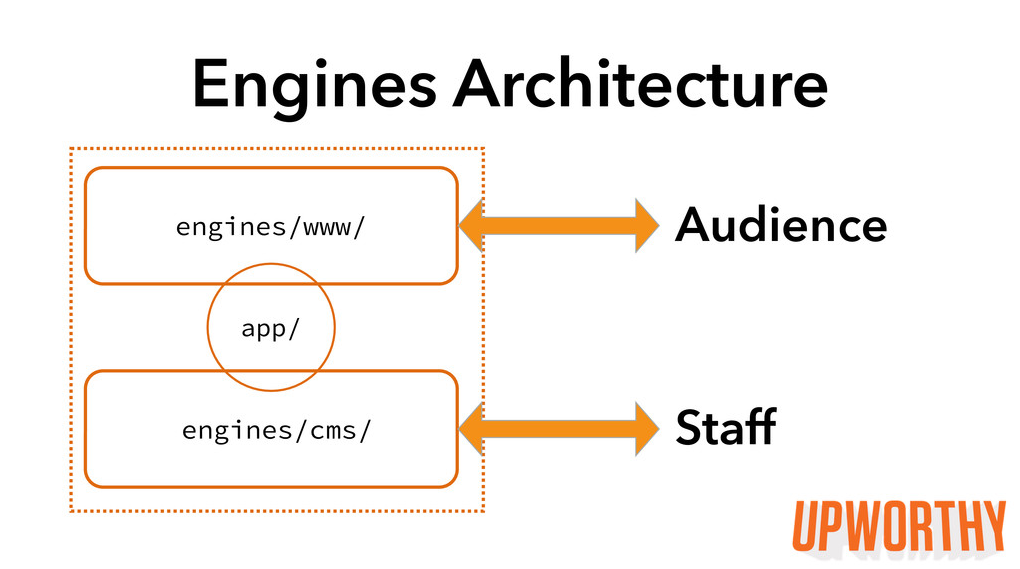
We launched our Rails Engine Architecture a little over a month ago, and since then, it has given us flexible deployment of our separate apps but with a more convenient development process. The gem that was housing our shared code is now an engine that we always load, and our CMS and WWW apps are two engines that we can load together (in local development, for example) or individually (on production machines).
 We drew heavily from TaskRabbit’s excellent blog post and sample app. In fact, we followed a very similar trajectory to theirs. We especially liked their BootInquirer model, which handles loading and mounting engines based on environment variables. Like them, we also chose to keep all of our tests in the top-level spec directory.
We drew heavily from TaskRabbit’s excellent blog post and sample app. In fact, we followed a very similar trajectory to theirs. We especially liked their BootInquirer model, which handles loading and mounting engines based on environment variables. Like them, we also chose to keep all of our tests in the top-level spec directory.
We took the following steps to migrate our code:
- Convert each of our main apps, WWW and CMS, into engines. They remained separate apps in separate repos but were namespaced and mountable.
- Create a container app with sample dummy engines. Set up our Browserify configs and BootInquirer model. Tweak our loading and mounting strategies to work on Heroku dynos.
- Drop the WWW and CMS engines into the container app.
- Convert our shared gem into an engine in the container app.
We encountered a few particularities in our implementation that might be useful to others:
Deploys to Heroku:
If you’re deploying to Heroku, you’ll probably want to have conditional logic in your Procfile to configure your dynos differently depending on which engine or engines you are mounting.
You can keep your Procfile clean by loading external scripts like so:
1
| |
And you can put your conditional logic in your script/launch-resque-worker file like so:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
Browserify-Rails on Engines:
The Rails asset pipelines in our two main apps diverged during their 18 months apart. We introduced Browserify-Rails to our WWW app while our CMS app remained on Sprockets-CommonJS. We use the following configurations to keep Browserify’s effects local to a single engine. Inside that engine’s engine.rb file, we added the following configs:
1 2 3 4 | |
Because we deploy to Heroku, we also had to tweak the package.json file. In fact, we have two package.jsons. Heroku’s Node.js buildpack runs npm install from the top level directory, so we have a package.json at the top level that looks like this:
1 2 3 4 5 6 7 8 | |
The scripts fields call the relevant npm commands within the engine that is actually using Browserify-Rails. We have a second package.json in the engines/www directory that contains the engine’s dependencies.
In our next design iteration, it’s likely that we’ll extract our front-end assets from Rails entirely and let our Rails app function as an API layer.
We’re also interested in ways we can extract API services from our current apps into their own simpler engines inside our container. We look forward to sharing our future iterations with you!