 R&D
R&DThis is a writeup of a talk I presented with Ryan Resella at RailsConf 2014.
When Upworthy launched in early 2012, we knew that if we executed well, we’d get popular quickly. Our mission, after all, is to drive massive amounts of attention to the topics that matter most. Being a website, that means lots and lots of web traffic. So from the very beginning Upworthy was engineered to handle viral traffic.
Buongiorno, Padrino
The early engineering team at Upworthy was composed of just two full-time staff: me as Founding Engineer and Tim Jones as CTO. We had very limited resources to build something from scratch, so we needed to choose a framework that emphasized developer productivity. I was a seasoned Ruby on Rails developer but at the time was souring on it. I felt that Rails was bloated and enforced opinions that I didn’t necessarily agree with. But I still loved writing Ruby code, and Sinatra’s low-level take on a web framework was very appealing to me.
I found Padrino as a happy middle ground between Rails and Sinatra. Padrino is essentially Sinatra with a little bit of Rails sprinkled in. It also took some really good ideas from the Python framework Django:
- First-class mountable apps. Unlike Rails engines, all Padrino projects must be made out of one or more mounted apps.
- Built-in admin area as a mountable app. While Rails Admin is great, the framework-level support for an admin area was a strong benefit.
- Middleware-centric. Padrino puts emphasis on a web app being a stack of middleware layers, which is a powerful concept for experienced web developers.
Experienced web developers, particularly those who’ve used the popular frameworks out there, eventually come to a realization: Frameworks fundamentally exist to help us respond to requests for HTML, CSS, JSON, JavaScript, and other resources. And so lower-level concepts like Rack and WSGI become very appealing, as do microframeworks built on top of them like Sinatra and Flask.
For launch on March 26, 2012, Upworthy was built on top of Padrino and deployed on Heroku. It was light and performant. It embraced Rack and Ruby. There was little magic. And it was unopinionated, letting us decide the exact libraries we wanted to use to accomplish our development goals.
Our Padrino project was composed of two mounted apps and a middleware layer for caching the public content pages:
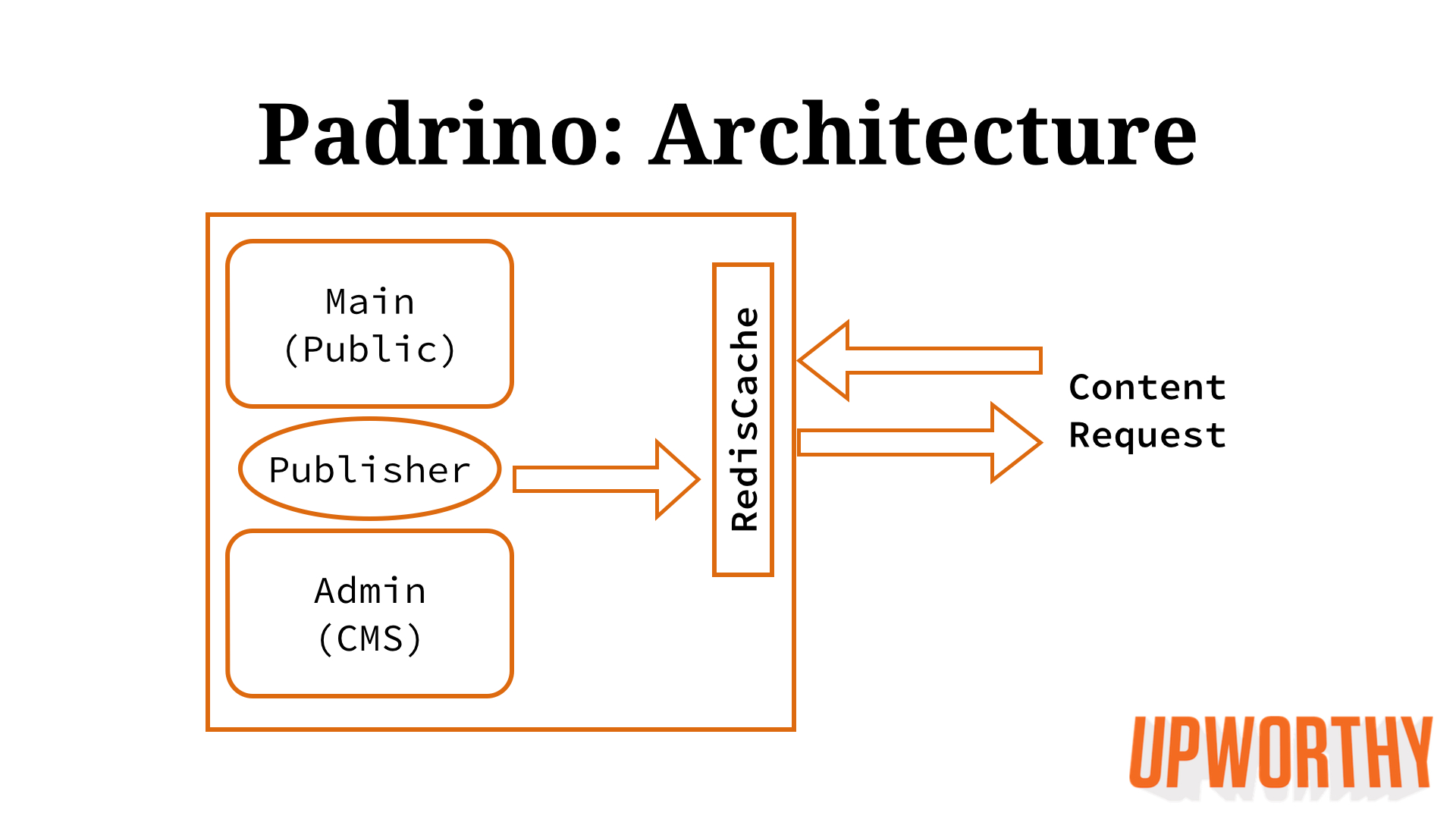
The middleware layer, called RedisCache, combined with the Publisher object created a system I dubbed “explicit caching.” It was inspired by the way Movable Type, the popular blogging engine of the 2000s, was architected: A writer would save their post to the database, and upon any database update, the system would re-render the necessary HTML to the filesystem. This resulted in a website that was extremely scalable using very limited resources because public traffic for a blog post hit the fast filesystem and didn’t make any database calls.
For our Padrino project, we built a Publisher object inside the Admin app. When curators updated the posts, the Publisher would make an HTTP call to the Public app (we actually used Capybara to simulate a real request) and saved the rendered HTML to the RedisCache. The RedisCache was a middleware layer that sat near the very front of our stack and quickly served our HTML pages to the public.
This worked well for us in the early months despite being an admittedly bespoke approach to solving the scaling problem. In June 2012, we hired a second Ruby/Rails engineer, Josh French. Within a few weeks of starting, he shared with us an important observation: “We should move to Rails.”
Moving To Rails
Josh was right. While the technical performance of Padrino was more than sufficient, we were bogged down by other factors. The ecosystem for libraries was good, particularly thanks to the popularity of Sinatra and Rack, but it wasn’t as great as Rails. The libraries that we were depending on, as well as the Padrino framework itself, were infrequently maintained when compared to their Rails counterparts. And as a growing startup, we needed to be able to recruit more engineers. Very few had heard of Padrino. The Rails community itself is an enormous asset, and something we missed.
In October 2012, Josh started the migration. We hired a third Rails engineer (Ryan Resella) in January 2013. Between off-and-on work by Josh and Ryan, it eventually took eight months to finally delete all Padrino code from our codebase.
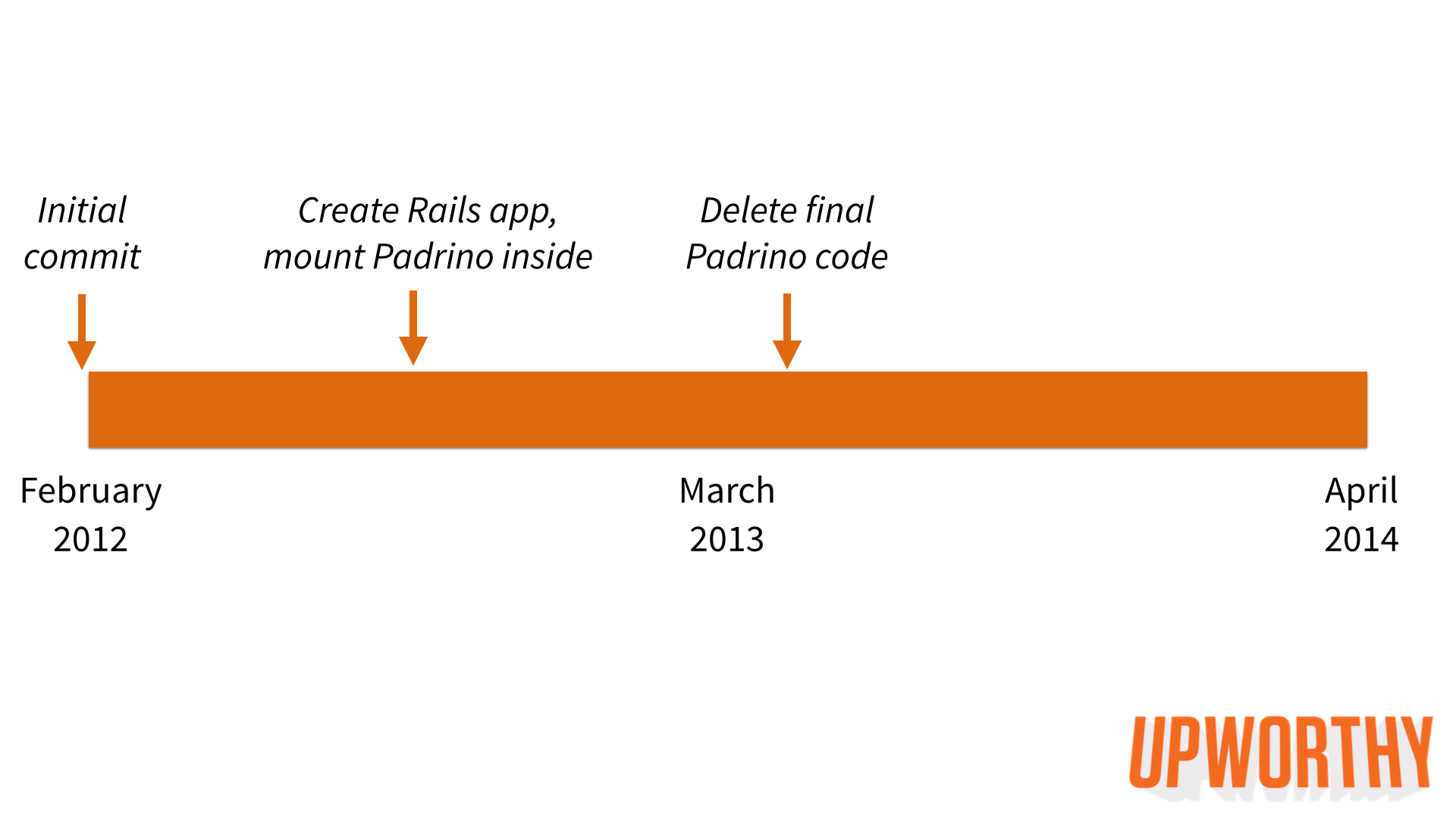
Why so long? We had other things to do! We needed to balance the demands of a growing company that was experiencing massively growing traffic. But thanks to the fact that Rails, Sinatra, and Padrino are all just built on top of Rack, we were able to live comfortably with a hybrid app for many months.
The steps we took to migrate were:
- Generate a new Rails app. Stick Padrino app in
lib/upworthy& mount it inroutes.rb. - Migrate models, utilities, and Rake tasks to Rails.
- Migrate assets from Jammit to the Rails Asset Pipeline.
- Migrate front-end views and controllers to Rails.
- Migrate CMS views to Bootstrap and CMS controllers to Rails.
Scaling Rails
For most of 2013, we were doing things The Rails Way. Our productivity noticeably increased. We were now a Rails monolith, jokingly referred to as a Monorail. All of our concerns were contained in a single Rails app: the front-end public site, the dynamic AJAX endpoints we use there, and the back-end CMS our curators use.
Doing things The Rails Way meant caching The Rails Way. We employed action caching for our content pages, backed by a memcached store. We served assets out of AWS S3 and Cloudfront. This worked mostly well for us, though we found ourselves routinely scaling our Heroku dynos during traffic spikes since the Rails app was directly serving our HTML.
In the fall of 2013, we decided to move our public HTML to a CDN, selecting Fastly. After we completed the move, all of our public assets (HTML, CSS, JS, images, and even some JSON) were being served out of Fastly’s global CDN. This was a huge win for us. Our site’s mobile load time improved significantly. We were able to turn off Rails action caching and instead manually set Fastly-optimized cache headers from our Rails controllers. We were able to dial down our Heroku dyno usage, though a CDN costs money too, so our overall hosting costs have increased. Most importantly, our public site hasn’t experienced any significant downtime since we moved to Fastly.
Moving To A Service-Oriented Architecture
There were downsides to a Monorail. Multiple concerns are stuck together within a single app. The codebase had expanded and god objects started to appear. Our team had grown to four Rails engineers, so we’d tend to trip over each other while building new features and fixing bugs. And while we haven’t experienced downtime on the public site, our public AJAX endpoints would become strained during traffic spikes, which would cause significant instability on our back-end CMS.
So we decided to split up our codebase into a service-oriented architecture. Josh performed the surgery in a few weeks, starting in December 2013 and finishing the next month:
- Decide how many services to split into. We chose to create two new Rails apps: www (the front end) and cms (the back end).
- Clone the Monorail into two separate git repos to maintain history. Each repo was now a new Rails app.
- Split up controllers, views, assets, and concerns among the two apps.
- Deploy each app as a distinct Heroku app.
- Switch Fastly to point at the new www app. This resulted in zero downtime.
- De-duplicate code between the two apps, creating a core gem (mostly models) to keep code DRY.
Here’s what our architecture looks like today:
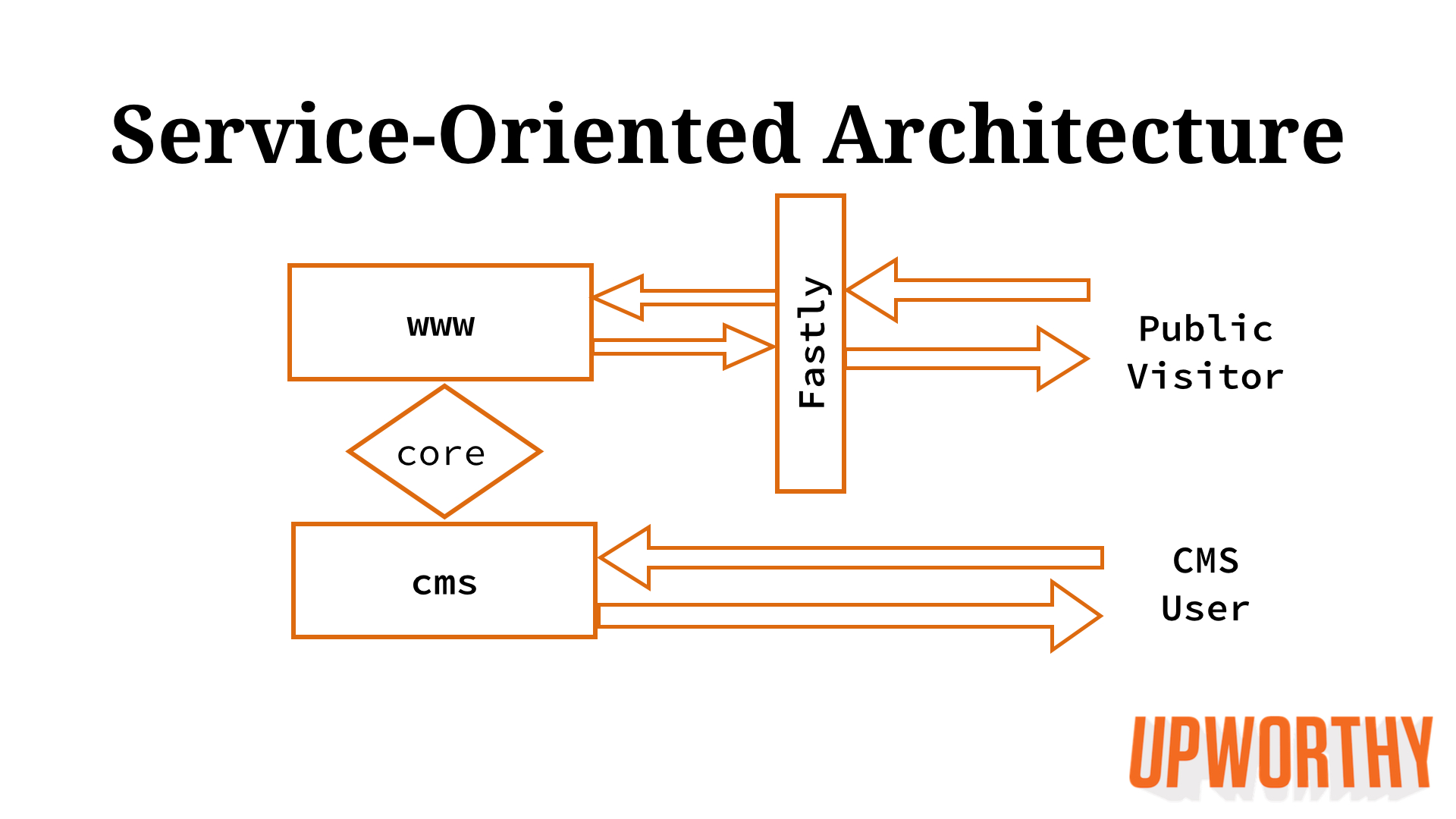
We can now properly scale the two apps: just a few Heroku dynos for cms and a bit more for the front-end www app serving our content and dynamic AJAX endpoints. Our cms no longer experiences instability when we have traffic spikes. Engineers don’t step on each other’s toes.
There have been some noticeable drawbacks. It has increased the complexity of our development setup. We have to coordinate deploys a bit better between the two Rails apps and the core Ruby gem. Migrating to a fully DRY setup is tedious, ongoing work.
Over the next few months, we’ll continue to consider breaking up the apps even more. In particular, www seems like a good candidate to split into a static site generator and a RESTful AJAX API. The apps currently communicate by sharing databases. We may want to write a more abstract data layer.
Looking back at the last two years, here’s how these big migrations have gone:
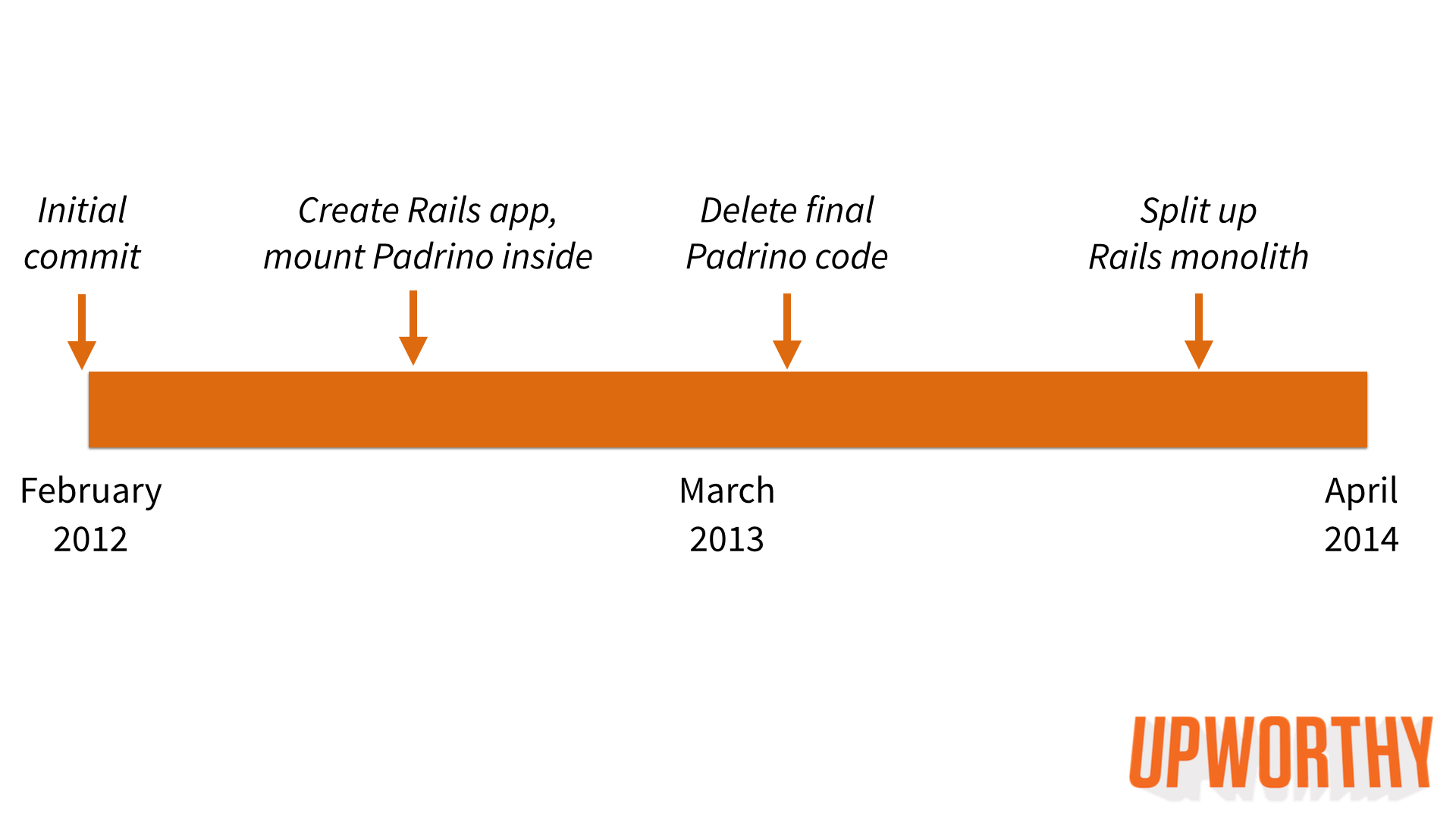
Notice how evenly spaced the changes have been. We’ll likely not complete our move to a service-oriented architecture until the end of summer 2014. This is completely acceptable for us. This is the reality that the engineering team at a fast-growing startup faces. We’re building a business, and we have more internal and external features on our to-do list than we can realistically ever get to.